
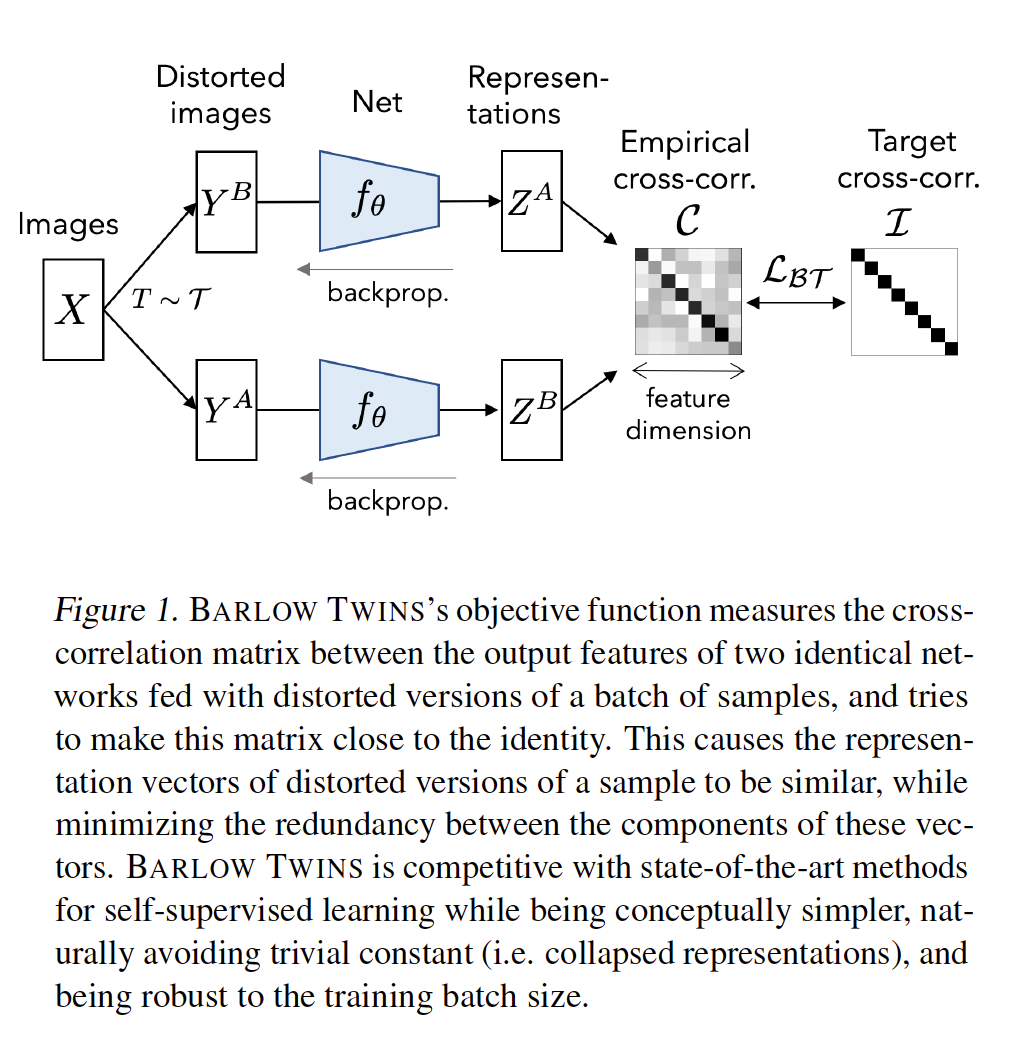
Absract: Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn representations which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant representations. Most current methods avoid such collapsed solutions by careful implementation details. We propose an objective function that naturally avoids such collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the representation vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. The method is called BARLOW TWINS, owing to neuroscientist H. Barlow’s redundancy-reduction principle applied to a pair of identical networks. BARLOW TWINS does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. It allows the use of very high-dimensional output vectors. BARLOW TWINS outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime, and is on par with current state of the art for ImageNet classification with a linear classifier head, and for transfer tasks of classification and object detection.
Own Summary: Barlow Twins uses 2 augmented views of the same image such as SimCLR but it introduces a new loss function which is inspired by Information Bottleneck. This loss function doesn't rely on large batch size or negative sample requirement as opposed to InfoNCE loss.
Like most other self-supervised vision algorithms Barlow Twins model consists of an encoder and a projector (MLP) layer. The definition of this module is fairly simple as below.
Instead of directly using BarlowTwinsModel by passing both an encoder and a projector, create_barlow_twins_model function can be used by minimally passing a predefined encoder and the expected input channels.
In the paper it's mentioned that MLP layer consists of 3 layers with first 2 layers having batchnorm followed by ReLU. The following function will create a 3 layer MLP projector with batchnorm and ReLU by default. Alternatively, you can change bn and nlayers. It is also noted in the paper that using larger hidden and projection size increases the downstream task performance.
Quote from the paper: Architecture The encoder consists of a ResNet-50 network (He et al., 2016) (without the final classification layer) followed by a projector network. The projector network has three linear layers, each with 8192 output units. The first two layers of the projector are followed by a batch normalization layer and rectified linear units.
You can use self_supervised.layers module to create an encoder. It supports all timm and fastai models available out of the box.
We define number of input channels with n_in, projector/mlp's hidden size with hidden_size, projector/mlp's final projection size with projection_size and projector/mlp's number of layers with nlayers.
encoder = create_encoder("tf_efficientnet_b0_ns", n_in=3, pretrained=False, pool_type=PoolingType.CatAvgMax)
model = create_barlow_twins_model(encoder, hidden_size=2048, projection_size=128, nlayers=2)
out = model(torch.randn((2,3,224,224))); out.shape
The following parameters can be passed;
- aug_pipelines list of augmentation pipelines List[Pipeline] created using functions from
self_supervised.augmentationsmodule. EachPipelineshould be set tosplit_idx=0. You can simply useget_simclr_aug_pipelinesutility to get aug_pipelines. - lmb $\lambda$ is the weight for redundancy reduction term in the loss function

BarlowTwins algorithm uses 2 views of a given image, and BarlowTwins callback expects a list of 2 augmentation pipelines in aug_pipelines.
You can simply use helper function get_barlow_twins_aug_pipelines() which will allow augmentation related arguments such as size, rotate, jitter...and will return a list of 2 pipelines, which we can be passed to the callback. This function uses get_multi_aug_pipelines which then get_batch_augs. For more information you may refer to self_supervised.augmentations module.
Also, you may choose to pass your own list of aug_pipelines which needs to be List[Pipeline, Pipeline] where Pipeline(..., split_idx=0). Here, split_idx=0 forces augmentations to be applied in training mode.
aug_pipelines = get_barlow_twins_aug_pipelines(size=28, rotate=False, jitter=False, bw=False, blur=False, stats=None, cuda=False)
aug_pipelines
path = untar_data(URLs.MNIST_TINY)
items = get_image_files(path)
tds = Datasets(items, [PILImageBW.create, [parent_label, Categorize()]], splits=GrandparentSplitter()(items))
dls = tds.dataloaders(bs=5, after_item=[ToTensor(), IntToFloatTensor()], device='cpu')
fastai_encoder = create_encoder('xresnet18', n_in=1, pretrained=False)
model = create_barlow_twins_model(fastai_encoder, hidden_size=1024, projection_size=1024)
aug_pipelines = get_barlow_twins_aug_pipelines(size=28, rotate=False, jitter=False, bw=False, blur=False, stats=None, cuda=False)
learn = Learner(dls, model, cbs=[BarlowTwins(aug_pipelines, print_augs=True),ShortEpochCallback(0.001)])
Also, with show_one() method you can inspect data augmentations as a sanity check. You can use existing augmentation functions from augmentations module.
b = dls.one_batch()
learn._split(b)
learn('before_batch')
axes = learn.barlow_twins.show(n=5)

learn.fit(1)
learn.recorder.losses