
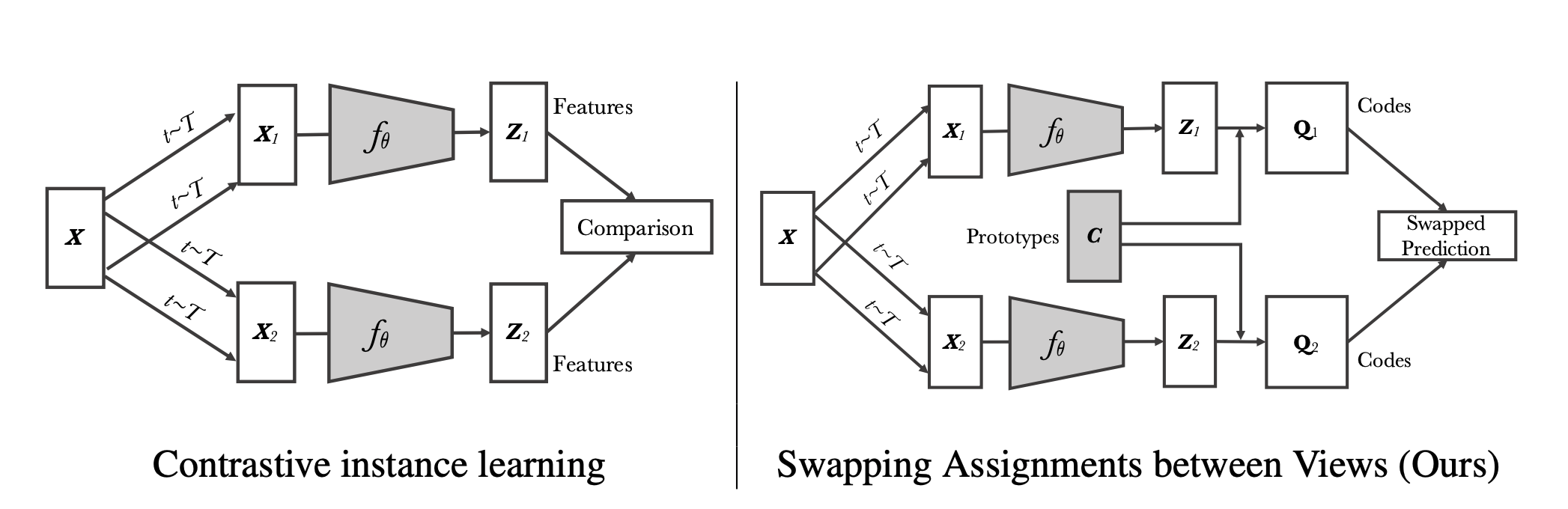
Absract: Unsupervised image representations have significantly reduced the gap with supervised pretraining, notably with the recent achievements of contrastive learning methods. These contrastive methods typically work online and rely on a large number of explicit pairwise feature comparisons, which is computationally challenging. In this paper, we propose an online algorithm, SwAV, that takes advantage of contrastive methods without requiring to compute pairwise comparisons. Specifically, our method simultaneously clusters the data while enforcing consistency between cluster assignments produced for different augmentations (or “views”) of the same image, instead of comparing features directly as in contrastive learning. Simply put, we use a “swapped” prediction mechanism where we predict the code of a view from the representation of another view. Our method can be trained with large and small batches and can scale to unlimited amounts of data. Compared to previous contrastive methods, our method is more memory efficient since it does not require a large memory bank or a special momentum network. In addition, we also propose a new data augmentation strategy, multi-crop, that uses a mix of views with different resolutions in place of two full-resolution views, without increasing the memory or compute requirements. We validate our findings by achieving 75:3% top-1 accuracy on ImageNet with ResNet-50, as well as surpassing supervised pretraining on all the considered transfer tasks.
encoder = create_encoder("tf_efficientnet_b0_ns", n_in=3, pretrained=False, pool_type=PoolingType.CatAvgMax)
model = create_swav_model(encoder, hidden_size=2048, projection_size=128, n_protos=3000)
multi_view_inputs = ([torch.randn(2,3,224,224) for i in range(2)] +
[torch.randn(2,3,96,96) for i in range(4)])
embedding, output = model(multi_view_inputs)
norms = model.prototypes.weight.data.norm(dim=1)
assert norms.shape[0] == 3000
assert [n.item() for n in norms if test_close(n.item(), 1.)] == []
The following parameters can be passed;
aug_pipelines list of augmentation pipelines List[Pipeline, Pipeline,...,Pipeline] created using functions from
self_supervised.augmentationsmodule. EachPipelineshould be set tosplit_idx=0. You can simply useget_swav_aug_pipelinesutility to get aug_pipelines. SWAV algorithm uses a mix of large and small scale crops.crop_assgn_ids indexes for large crops from aug_pipelines, e.g. if you have total of 8 Pipelines in the
aug_pipelineslist and if you define large crops as first 2 Pipelines then indexes would be [0,1], if as first 3 then [0,1,2] and if as last 2 then [6,7], so on.K is queue size. For simplicity K needs to be a multiple of batch size and it needs to be less than total training data. You can try out different values e.g.
bs*2^kby varying k where bs i batch size. You can pass None to disable queue. Idea is similar to MoCo.queue_start_pct defines when to start using queue in terms of total training percentage, e.g if you train for 100 epochs and if
queue_start_pctis set to 0.25 then queue will be used starting from epoch 25. You should tune queue size and queue start percentage for your own data and problem. For more information you can refer to README from official implementation.temp temperature scaling for cross entropy loss similar to
SimCLR.
SWAV algorithm uses multi-sized-multi-crop views of image. In original paper 2 large crop views and 6 small crop views are used during training. The reason of using smaller crops is to save memory and perhaps it also helps model to learn local features better.
You can manually pass a mix of large and small scale Pipeline instances within a list to aug_pipelines or you can simply use get_swav_aug_pipelines() helper function below:
- num_crops Number of large and small scale views to be used.
- crop_sizes Image crop sizes for large and small views.
- min_scales Min scale to use in RandomResizedCrop for large and small views.
- max_scales Max scale to use in RandomResizedCrop for large and small views.
I highly recommend this UI from albumentations to get a feel about RandomResizedCrop parameters.
Let's take the following example get_swav_aug_pipelines(num_crops=(2,6), crop_sizes=(224,96), min_scales=(0.25,0.05), max_scales=(1.,0.14)). This will create 2 large scale view augmentations with size 224 and with RandomResizedCrop scales between 0.25-1.0. Additionally, it will create 2 small scale view augmentations with size 96 and with RandomResizedCrop scales between 0.05-0.14.
Note: Of course, the notion of small and large scale views depend on the values you pass to crop_sizes, min_scales, and max_scales. For example, if I we flip crop sizes from previous example as crop_sizes=(96,224), then in this case first 2 views will have image resolution of 96 and last 6 views will have 224. For reducing confusion it's better to make relative changes, e.g. if you want to try different parameters always try to keep first values for larger resolution views and second values for smaller resolution views.
- **kwargs This function uses
get_multi_aug_pipelineswhich then usesget_batch_augs. For more information you may refer toself_supervised.augmentationsmodule. kwargs takes any passable argument toget_batch_augs
crop_sizes defines the size to be used for original crops and low resolution crops respectively. num_crops define N: number of original views and V: number of low resolution views respectively. min_scales and max_scales are used for original and low resolution views during random resized crop. eps is used during Sinkhorn-Knopp algorithm for calculating the codes and n_sinkh_iter is the number of iterations during it's calculation. temp is the temperature parameter in cross entropy loss
path = untar_data(URLs.MNIST_TINY)
items = get_image_files(path)
tds = Datasets(items, [PILImageBW.create, [parent_label, Categorize()]], splits=GrandparentSplitter()(items))
dls = tds.dataloaders(bs=4, after_item=[ToTensor(), IntToFloatTensor()], device='cpu')
fastai_encoder = create_fastai_encoder(xresnet18, n_in=1, pretrained=False)
model = create_swav_model(fastai_encoder, hidden_size=2048, projection_size=128)
aug_pipelines = get_swav_aug_pipelines(num_crops=[2,6],
crop_sizes=[28,16],
min_scales=[0.25,0.05],
max_scales=[1.0,0.3],
rotate=False, jitter=False, bw=False, blur=False, stats=None,cuda=False)
learn = Learner(dls, model,
cbs=[SWAV(aug_pipelines=aug_pipelines, crop_assgn_ids=[0,1], K=None), ShortEpochCallback(0.001)])
b = dls.one_batch()
learn._split(b)
learn('before_batch')
learn.pred = learn.model(*learn.xb)
Display 2 standard resolution crops and 6 additional low resolution crops
axes = learn.swav.show(n=4)

learn.fit(1)
learn.recorder.losses