
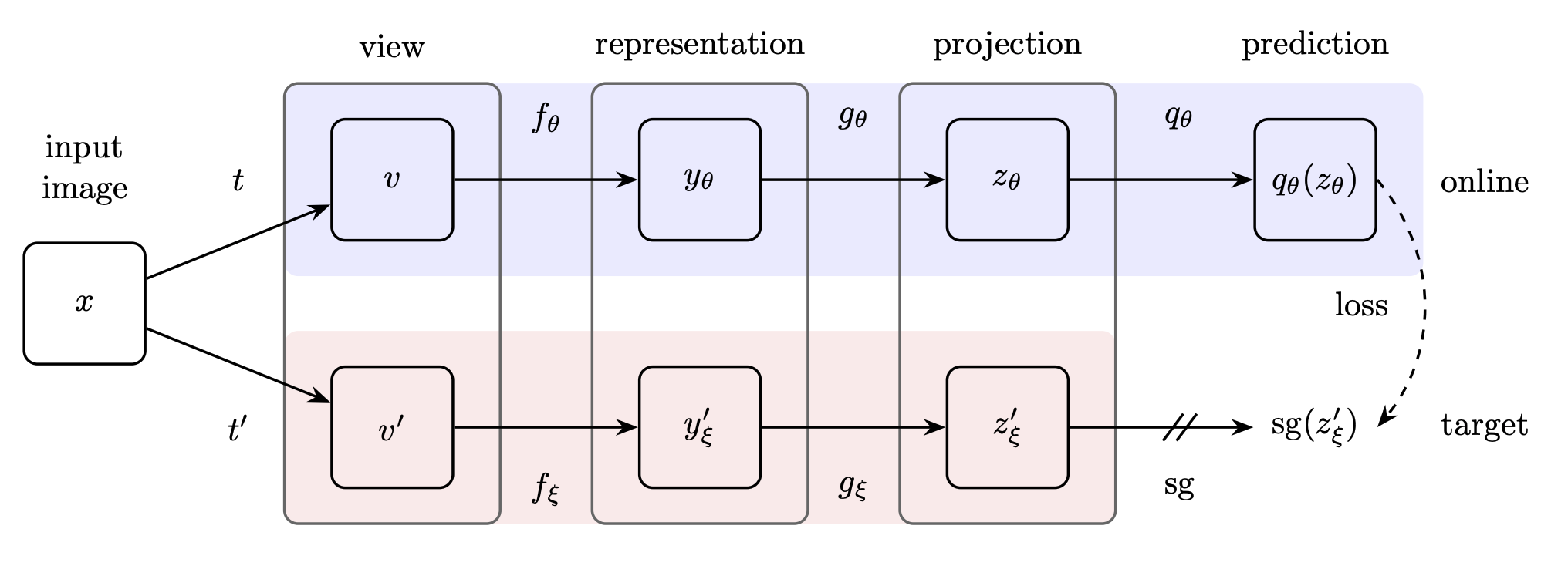
Abstract: We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network. While state-of-the art methods rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches 74:3% top-1 classification accuracy on ImageNet using a linear evaluation with a ResNet-50 architecture and 79:6% with a larger ResNet. We show that BYOL performs on par or better than the current state of the art on both transfer and semi-supervised benchmarks. Our implementation and pretrained models are given on GitHub.3
You can either use BYOLModel module to create a model by passing predefined encoder, projector and predictor models or you can use create_byol_model with just passing predefined encoder and expected input channels.
You may notice projector/MLP module defined here is different than the one defined in SimCLR, in the sense that it has a batchnorm layer. You can read this great blog post for a better intuition on the effect of the batchnorm layer in BYOL.
encoder = create_encoder("tf_efficientnet_b0_ns", n_in=3, pretrained=False, pool_type=PoolingType.CatAvgMax)
model = create_byol_model(encoder, hidden_size=2048, projection_size=128)
out = model(torch.randn((2,3,224,224)), torch.randn((2,3,224,224)))
out[0].shape, out[1].shape
The following parameters can be passed;
- aug_pipelines list of augmentation pipelines List[Pipeline] created using functions from
self_supervised.augmentationsmodule. EachPipelineshould be set tosplit_idx=0. You can simply useget_byol_aug_pipelinesutility to get aug_pipelines. - m is momentum for target encoder/model update, a similar idea to MoCo.
BYOL algorithm uses 2 views of a given image, and BYOL callback expects a list of 2 augmentation pipelines in aug_pipelines.
You can simply use helper function get_byol_aug_pipelines() which will allow augmentation related arguments such as size, rotate, jitter...and will return a list of 2 pipelines, which we can be passed to the callback. This function uses get_multi_aug_pipelines which then get_batch_augs. For more information you may refer to self_supervised.augmentations module.
Also, you may choose to pass your own list of aug_pipelines which needs to be List[Pipeline, Pipeline] where Pipeline(..., split_idx=0). Here, split_idx=0 forces augmentations to be applied in training mode.
path = untar_data(URLs.MNIST_TINY)
items = get_image_files(path)
tds = Datasets(items, [PILImageBW.create, [parent_label, Categorize()]], splits=GrandparentSplitter()(items))
dls = tds.dataloaders(bs=5, after_item=[ToTensor(), IntToFloatTensor()], device='cpu')
fastai_encoder = create_encoder('xresnet18', n_in=1, pretrained=False)
model = create_byol_model(fastai_encoder, hidden_size=4096, projection_size=256, bn=True)
aug_pipelines = get_byol_aug_pipelines(size=28, rotate=False, jitter=False, bw=False, blur=False, stats=None, cuda=False)
learn = Learner(dls, model, cbs=[BYOL(aug_pipelines=aug_pipelines, print_augs=True), ShortEpochCallback(0.001)])
learn.summary()
b = dls.one_batch()
learn._split(b)
learn('before_fit')
learn('before_batch')
axes = learn.byol.show(n=5)

learn.fit(1)
learn.recorder.losses